RLAC: REINFORCEMENT LEARNING WITH ADVERSARIAL CRITIC FOR FREE-FORM GENERATION TASKS
1Shanghai Jiao Tong University2University of California, Berkeley3Carnegie Mellon University
 paper
paperTL;DR
Instead of using static reward models or critics, RLAC trains a dynamic critic alongside the generator (RL policy), using an adversarial two-player game formulation. This enables verifying outputs on free-form generation tasks without needing to enumerate or identify all possible rubrics or manually engineer robust reward models.
Abstract
Open-ended generation tasks require outputs to satisfy diverse and often implicit
task-specific evaluation rubrics. The sheer number of relevant rubrics leads to prohibitively
high verification costs and incomplete assessments of a response, making
reinforcement learning (RL) post-training with rubric-based rewards difficult to
scale. This problem is exacerbated by the fact that often the best way to combine
these rubrics into one single reward is also highly prompt-specific. We propose
Reinforcement Learning with Adversarial Critic (RLAC), a post-training approach
that addresses these challenges via dynamic rubric verification. Our approach
employs a large language model (LLM) as a critic that dynamically identifies
only the most likely failure modes (e.g., a factual error or unhandled edge case),
which are then verified by an external validator to optimize both generator and
critic jointly. By training both the generator and the critic, this game enhances the
critic’s error detection and the generator’s output quality while reducing required
verifications. Our experiments demonstrate that RLAC improves factual accuracy
in text generation and correctness in code generation, while also outperforming
exhaustive verification and reward model methods. We show that dynamic critics
are more effective than fixed critics, showcasing the potential of RLAC for scaling
RL post-training to free-form generation tasks.
Enumerative methods verify outputs by enumerating evaluation rubrics exhaustively or approximately; reward-model approaches replace explicit verification with a pretrained model that outputs scalar rewards; and RLAC dynamically identifies and validates likely errors.
Evaluation
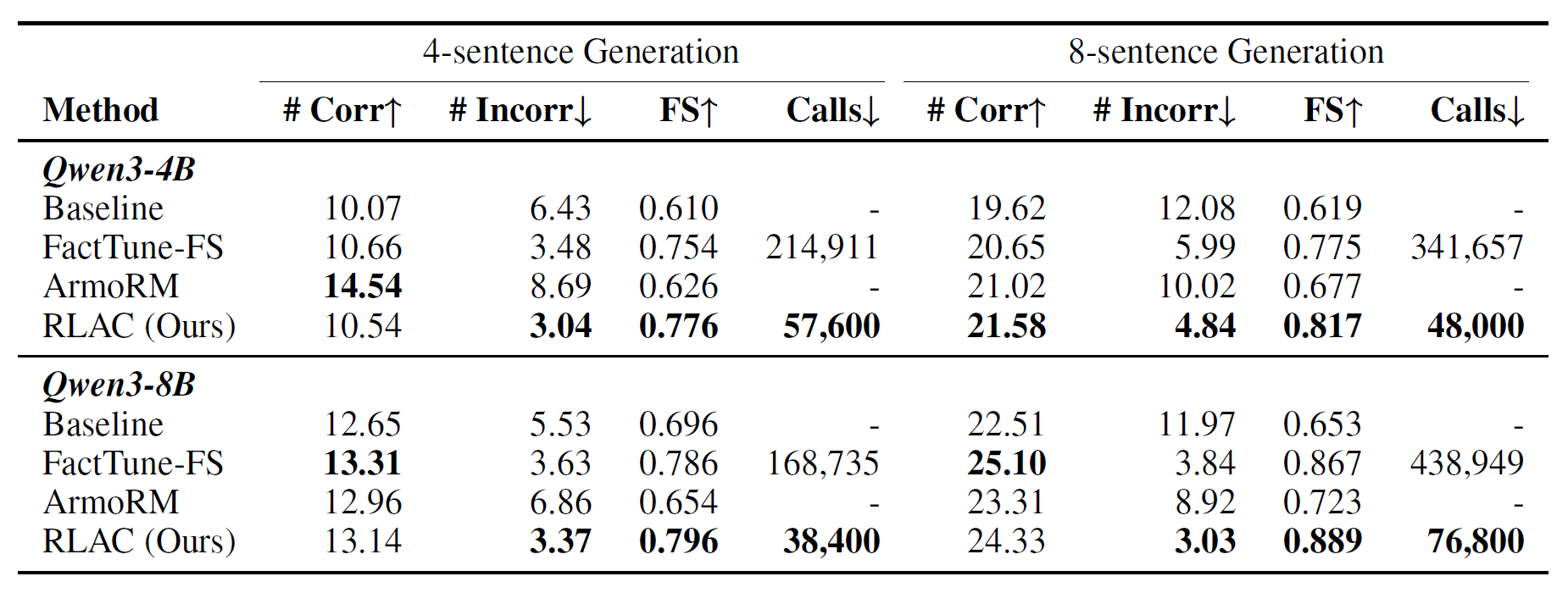
Performance Comparison on Factual Text Generation
We perform RL training with two policy models, Qwen3-4B and Qwen3-8B.
RLAC achieves the highest FactScore across both model sizes and generation lengths.
These results demonstrate that RLAC scales more efficiently with increasing generation
complexity while preserving factual accuracy.
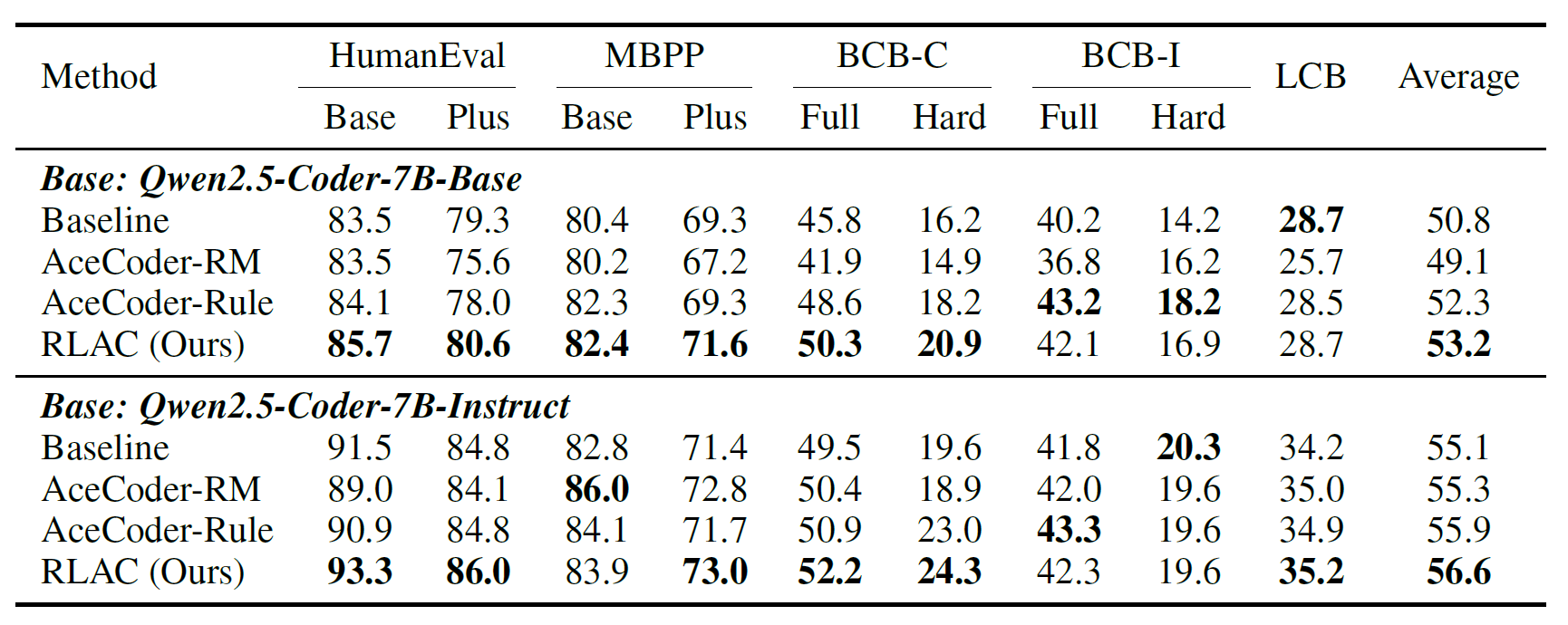
Performance Comparison on Code Generation
We perform RL training with two policy models,
Qwen2.5-Coder-7B-Base and Qwen2.5-Coder-7B-Instruct.
RLAC achieves the highest average Pass@1 across HumanEval,
MBPP, BigCodeBench, and LiveCodeBench benchmarks,
outperforming both enumerative (AceCoder-Rule) and reward-model (AceCoder-RM) baselines.
Adversarial Critic Matters
We compare static and adversarial training of the critic
to evaluate its role in guiding the generator.
As shown in Table 3, the adversarially trained critic increases the number of
correct facts (21.6 vs. 17.8) while keeping errors low.
In contrast, the static critic achieves a slightly higher FactScore by reducing the
number of generated facts, indicating over-precision rather than genuine improvement.
These results highlight that dynamic,
adversarial critic training is crucial, it continuously adapts to the generator’s behavior,
preventing reward hacking and sustaining meaningful supervision.

Reference
BibTex
@misc{wu2025rlacreinforcementlearningadversarial,
title={RLAC: Reinforcement Learning with Adversarial Critic for Free-Form Generation Tasks},
author={Mian Wu and Gavin Zhang and Sewon Min and Sergey Levine and Aviral Kumar},
year={2025},
eprint={2511.01758},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2511.01758},
}